GPUサーバーとは?導入メリットや活用シーン、選定ポイントを解説

GPUサーバーは、GPUの並列計算でAIの学習・推論やHPC(科学技術計算)、3D可視化を高速に実行できる計算基盤です。GPUサーバーの活用により、開発期間の短縮や新規サービス創出、長期的なROI向上が期待できます。この記事では、GPUサーバーの基礎知識から導入するメリット、活用シーン、導入形態の比較、選定のポイントまで、詳しく解説します。
目次
GPUサーバーとは

GPUサーバーとは、画像処理向けに発展したGPU(Graphics Processing Unit)の大規模な並列演算能力を、AIやシミュレーションなど業務用途に活かすために設計されたサーバーのことです。ここでは、GPUサーバーの定義や、CPUサーバーとの違い、圧倒的な計算能力、ビジネスにおける重要性について解説します。
GPUサーバーの定義
GPUサーバーは「1台のサーバー筐体に1枚以上のGPUを搭載し、多数のコア(演算器)による並列演算を業務用途に活用するための計算基盤」を指すのが一般的です。
GPUは元来グラフィックス処理を目的に設計されましたが、現在は汎用計算(AIやシミュレーションなど)にも広く活用されています。
GPUサーバーは単体デバイスとしてのGPUとは区別され、CPUやメモリ、ストレージ、ネットワーク、場合によっては高速なGPU間接続までを含めたインフラ製品です。ジョブの実行順序を自動的に管理したり、複数のユーザーが同時にリソースを使えるように仮想化したりする仕組みによって、組織全体で計算資源を無駄なく活用できます。多くの分野・業界で、AI学習・推論、データ分析、可視化などへの活用を前提に導入が進んでいます。
CPUサーバーとの違い
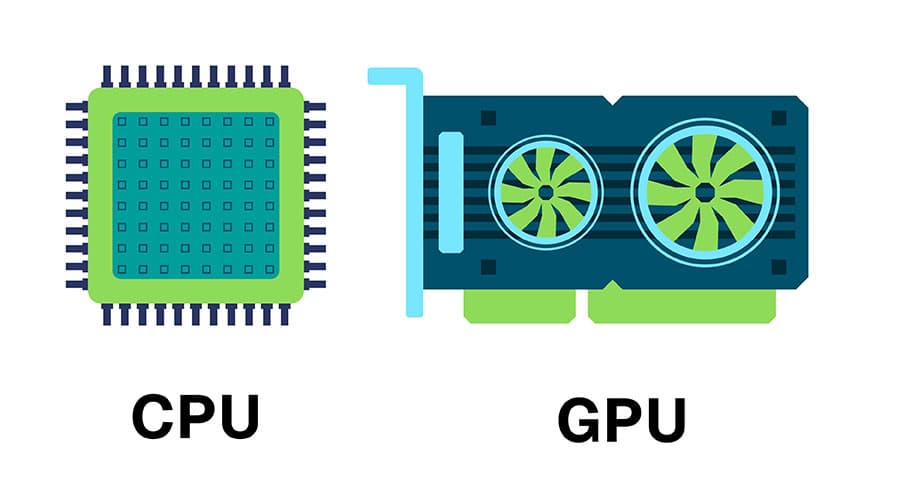
CPUサーバーとの主な違いは、計算の「並列性」と「メモリの設計」にあります。
- CPU(頭脳役):
少数の高性能なコアで構成されます。複雑な制御や条件分岐が多いタスクを「直列的(順番に)」に高速処理するのが得意です。 - GPU(実行役):
数千から万単位のシンプルなコアを持ちます。大量のデータに対し、同じ命令を「並列的(一斉に)」に処理することに特化しています。
メモリ設計の違いも重要です。 GPUは、その膨大な数のコアにデータを絶え間なく供給し続けるため、VRAMと呼ばれる大容量・高帯域の専用メモリを搭載しています。この設計により、行列演算のような大量の計算でもデータ詰まりを起こしにくい構造になっています。
端的には、分岐の少ない同種演算の大量処理はGPU向き、複雑な制御や条件分岐が多い処理はCPU向きと理解するとよいでしょう。
GPUサーバーの圧倒的な計算能力
GPUサーバーの高い計算能力は、同じ種類の処理を同時並行で実行できるハードウェア設計によって実現されています。この性能を最大限に引き出すのが、ランタイムやライブラリ、フレームワークなどのソフトウェア群です。ハードウェア面では、多数のコアを束ねて行列演算や畳み込みを一斉に実行できるため、ディープラーニングや数値シミュレーションといった大規模計算を効率的に実行できます。
たとえば、NVIDIA製GPUの「Tensorコア」は、AI計算などを直接高速化するハードウェア機能です。これに加え、GPUを動かすための「CUDAプラットフォーム」やソフトウェアである各種ライブラリが連携することで、AIの学習やシミュレーションのように計算量が多い処理を高速に進められます。
さらに大容量のVRAMと高いメモリ帯域、GPU間の高速通信を備えているため、大規模バッチ処理や三次元格子計算のような重いタスクでも、高い稼働率でリソースを維持できることも強みです。結果として同一期間に実行可能なジョブ数が増え、実験サイクルの高速化につながります。
ビジネスにおけるGPUサーバーの重要性
特にAI開発やHPC分野に関連するビジネスにおいて、GPUサーバーは開発と研究のリードタイム短縮に直結します。機械学習や生成AI、データマイニングでの学習・推論の高速化によってモデル改良の反復回数が増えるため、製品・サービス投入までの時間短縮に寄与します。創薬や材料設計、CAEといったHPC分野では、高精度シミュレーションを現実的な時間でより多く回せることから、探索の幅と深さを強化できるでしょう。近年は、GPU需要の高まりに合わせてデータセンター投資が加速し、電力・冷却・ネットワークを含むインフラ戦略の中核リソースとして位置付けられつつあります。今後のGPUサーバー活用戦略としては、オンプレミスとクラウドを使い分けながら、ますます高まっていく計算需要を満たす体制を整えることが重要です。
企業がGPUサーバーを導入するメリット
企業がGPUサーバーを導入する主なメリットは以下のとおりです。
- データ処理の高速化
- AI/DXの推進基盤を確立
- 長期的な投資対効果(ROI)
以下、それぞれ解説します。
データ処理の高速化
GPUサーバーは同種演算を大量並列で処理できるため、学習・推論・HPCの所要時間を大幅に短縮します。さらに、GPU最適化フレームワークやメーカー独自の処理技術を活用し、CPUに比べて一度に処理できるデータ量を安定して高く保てるのも大きなメリットです。結果として、大量かつ反復的なトライアンドエラーを高速で繰り返すことができます。高速化に伴った学習時間の削減は、ジョブ回転数の増加と意思決定の迅速化につながり、製品投入までのリードタイムを短縮します。
AI/DXの推進基盤を確立
GPUサーバーは企業のAI/DXを支える計算基盤となります。基盤モデル開発や生成AI活用、RAG/検索拡張などのワークロードを、オンプレミスやクラウドで継続的に運用でき、適切に管理することで部署横断的に再利用可能な知見資産として蓄積可能です。
日本では公的支援による生成AIの計算資源拡充やクラウドGPU整備も進められており、研究領域(創薬、材料設計、CAEなど)から業務アプリ(チャット検索、文章要約、コーディング支援など)まで、幅広い分野での基盤の内製および共同利用が促進されています。
長期的な投資対効果(ROI)
長期的な投資対効果を高めるには、GPUリソースを仮想化・共有して、部署をまたいで利用できる環境を整えることが有効です。仮想化ソフトウェア(NVIDIA vGPUなど)により、1台のGPUサーバーを複数ユーザーやワークロードで分割して利用でき、設備集約と運用管理を効率化できます。また、利用パターンや規模に応じてオンプレミス、クラウド、ハウジングを使い分けることで、初期投資と運用コストのバランスを最適化し、総所有コスト(TCO:Total Cost of Ownership)の抑制とROI向上を図れます。
GPUサーバー運用における注意点
GPUサーバーの導入では、初期費用と継続的な運用コストの両面から、費用対効果を総合的に判断する必要があります。また、高密度化に伴う電力消費と冷却対策にも注意しなければなりません。
高額な初期費用と継続的な運用コスト
初期費用は、サーバー本体とGPU構成に加えて、ラック・配線、電源設備、保守体制の整備などの周辺費用も積み上がります。サーバー本体の価格は、エントリーモデルで30万〜100万円程度ですが、用途やGPU枚数が増えると数百万円〜数千万円規模になることもあります。初期投資を抑えてすぐにGPU環境を利用したい場合は、クラウドやレンタル、データセンターでの運用を検討するとよいでしょう。
継続的にかかる運用コストは、電力・空調、保守要員、ソフトウェアサブスクリプション、更新・増設計画まで含めたTCOを確認することが不可欠です。GPUサーバーの導入形態によっても費用構造が異なるため、3〜5年程度の利用計画に基づく総額で評価します。
こうした課題に対し、初期投資の負担を抑えながらGPU環境をすぐに利用できる選択肢も登場しています。
シーイーシーでは、最新の高性能GPUサーバーを初期費用0円で導入・運用できる「スターターパック for GPUサーバー」を用意しました。HPCやAI開発に適した構成をすぐに利用できます。さらに、導入前の性能検証や運用相談、コスト試算のサポートも行っており、初めてGPUを導入する企業様でも安心してスタートできます。
詳しくは以下のページをご覧ください。
お客様のDX実現を支援するシーイー…


スターターパック for GPUサーバー | シーイーシーデータセンター
最新の高スペックなGPUサーバーをお客様の資産として持たずに、初期費用0円でご利用いただけるサービスです。データマイニング、ブロックチェーン、AI、機械学習などに活用…
大量の電力消費と冷却対策の必要性
最新GPUはTDP*が数百W級で、複数搭載サーバーはラック当たりの発熱密度が高くなります。空冷のみでは熱設計が厳しくなるケースがあり、背面ドア熱交換器や直接液冷、液浸などの液冷オプションも含めた設備設計が必要です。施設側では配管・熱搬送・排熱計画、電源容量の見直し、PDU*設計などを検討し、必要に応じて液冷対応の高密度ラックを採用します。一般的なオフィス環境では適切に管理するのが困難なため、安定稼働のためには専用のデータセンターで運用することが推奨されます。
シーイーシーでは、高負荷・高消費電力のGPUサーバーを安定稼働させたいお客様に向けて、「GPU・HPC対応 高負荷サーバーハウジングサービス」を提供しています。専用データセンターに設置することで、電源・空調・ネットワークといったインフラの負担を軽減し、GPUの性能を最大限に発揮できます。
また、利用電力に応じた柔軟な料金体系を採用しており、無駄のないコスト運用が可能です。監視・保守体制も整備されており、障害時の迅速な対応や災害対策にも対応。高密度・高負荷環境でも安定稼働を維持でき、AI開発やシミュレーションなどの重要な計算処理を長期にわたって安心して実行できます。
- TDP(Thermal Design Power):「熱設計電力」の意で、半導体が想定最大負荷で放出する設計上の目安値。
- PDU(Power Distribution Unit):ラック内に配備する電源分配装置のこと。
GPUサーバーの多様な活用シーン
ここでは、GPUサーバーが実際にどのようなビジネスシーンで活用されているかを具体的に紹介します。
AI開発・機械学習における高速な学習と推論
GPUサーバーは、生成AI/機械学習の学習・推論において欠かせない計算基盤であり、大規模データの並列処理により開発サイクルを加速します。LLM開発や業務AI(検索・要約・不正検知・チャットボットなど)まで幅広いユースケースで効果を発揮します。国内ではABCI3.0*などの大規模AI計算基盤が一般提供され、最新GPUを多数搭載した学習環境を確保しやすくなりました。これにより、基盤モデル開発から社会実装までの推進力が高まることが期待されています。
- 国立研究開発法人 産業技術総合研究所が提供する、生成AIなどの最先端AI技術の研究開発を目的とした大規模AIクラウド計算システム
HPC(科学技術計算)と高精度なシミュレーション
GPUサーバーは、HPCやシミュレーション分野でも重要な役割を果たしています。
GPUは多数の演算コアを同時に動かして複雑な数値計算を高速処理できるため、これまで時間やコストの面で実行が難しかった大規模な解析(流体の動き、分子の挙動、構造解析など)を現実的な時間で行えるようになりました。
特に最新のデータセンター向けGPU(例:NVIDIA H100やA100)は、高い計算精度と広いメモリ帯域を備えており、NVLinkやInfiniBandといった高速通信技術を使って複数GPU間で効率的にデータをやり取りできます。これにより、大規模なシミュレーションでも安定した処理性能を発揮します。
また、近年はソフトウェア面での最適化も進んでおり、分子動力学などの科学アプリケーションでは、GPUを活かしたアルゴリズムや分散処理技術の改良によって、さらに高い計算効率を実現しています。
3Dグラフィックス・映像・CAD・デジタルツイン
GPUサーバーは、3Dグラフィックス制作や映像制作、CAD分野で利用が進んでおり、製造・建築・空間デザインの分野でも幅広く応用されています。GPUの高速並列処理により、高品質な画像生成やレンダリング時間の大幅な短縮が可能です。
特にCAD分野では、複雑な設計データをリアルタイムに可視化でき、設計検証の効率が向上しています。さらに、VDI(仮想デスクトップ)やvGPU(仮想GPU)により、自治体や企業でもGPUリソースを安全に共有でき、デジタルツインやVR/ARなどの可視化ワークロードの展開が進んでいます。
デジタルツインについてはこちらの記事でも解説しています
あわせて読みたい

デジタルツインとは?主要技術やメリット、活用事例をわかりやすく解説
デジタルツインは、現実世界のあらゆるものを仮想空間に再現し、シミュレーションや予測に活用する最先端技術です。IoTやAI、5Gなどの複数の先進技術を組み合わせること…
GPUサーバー導入形態の比較

企業がGPUサーバーを導入する際の主な選択肢として、クラウド、レンタル、自社運用(オンプレミス)、データセンターでのハウジングを比較し、それぞれの特徴やメリット・デメリット、適した目的/用途を説明します。
クラウド
クラウドは初期投資を抑えつつ、柔軟にGPU環境を拡張できる最も手軽な選択肢です。
特徴
- 主要なクラウドで、最新世代のGPUを利用できる(ただし、地域や時期により可用性が制限される場合がある)。
- 必要な時に台数を増やせたり、使った分だけ支払えたりするなど、運用の柔軟性が高い。
メリット
- 初期費用が小さく、検証〜本番の段階的拡張が容易。
- 高速ネットワーク(InfiniBandやNVLink/NVSwitch)により、分散学習やHPCに適する。
デメリット
- 長期運用や常時稼働では費用が嵩みやすい。
- ガバナンス要件によりデータ所在や回線設計の追加検討が必要。
目的/用途
- 短期検証やピーク時のみの増強など、一定期間だけ利用したい場合。
- 迅速な実験サイクルを回したい場合。
レンタル
レンタルでは、自社購入せずに、物理GPUサーバーを一定期間だけ占有利用できる形態です。
特徴
- 事業者の用意するGPUサーバーを月額/時間課金で占有利用する形態。
- 物理サーバーを直接利用できるベアメタル提供や短期契約に対応するサービスがある。
メリット
- オンプレミスより初期費用が抑えやすい。
- 設備運用(電源・空調・監視)の多くを委託できる。
- GPU構成の変更やモデルの更新にも柔軟に対応可能。
デメリット
- カスタマイズ性はあまり高くなく、在庫・型番の制約を受ける。
- ネットワーク環境や周辺設計は事業者の仕様に依存する。
目的/用途
- 一定期間のプロジェクトに利用したい場合。
- オンプレ検討前の実機評価をしたい場合。
- 設備投資をなるべく抑えたい場合。
オンプレミス
自社で設備を保有・管理し、セキュリティと自由度を重視した運用が可能です。
特徴
- 自社設備として調達・設置・運用する形態。
- 機密データの閉域処理や既存システムとの密結合に適する。
メリット
- 構成の自由度が高く、セキュリティ/ガバナンス要件を自社基準で統制できる。
- 長期・高負荷の常時稼働なら、TCOで優位になりやすい。
デメリット
- 消費電力/発熱量が大きいため専用設備が必要になるなど、管理・保守のハードルが高い。
- 安定稼働のために、保守要員の配置と定期的な更新計画が必要。
目的/用途
- 常時稼働の学習やシミュレーションを行いたい場合。
- 厳格なデータ所在要件を維持したい場合。
- 社内システムとの超低遅延連携が必要な場合。
ハウジング
自社で保有したGPUサーバーを、専門設備を備えたデータセンターで運用する方法です。
特徴
- 自社所有のGPUサーバーをデータセンターのラックに設置し、電源・空調・回線・運用の一部を委託する運用手法。
- 高電力・高発熱に対応した設備を活用できる。
メリット
- 電源・冷却・回線など、社内設置では対応が難しい課題を解決できる。
- 想定利用電力での料金設計も可能なケースがある。
- スケール時はラック/電源の追加で拡張も可能。
デメリット
- 拠点間に距離があると、運用・保守作業が煩雑になる。
- データセンター仕様に合わせた機器選定や持ち込みルールへの適合が必要。
目的/用途
- 自社資産で運用したいがオンプレミスでは困難な場合。
- 高密度電力/液冷対応が必要なGPUサーバーを活用したい場合。
- 持続的な常時稼働で運用コストを最適化したい場合。
GPUサーバー選定のポイント

GPUサーバーを選定する際は、目的と用途に合わせて、サーバー性能やコスト、サポート体制を総合的に評価することが大切です。以下、それぞれのポイントを解説します。
目的/用途
ここでは、GPUサーバーの代表的な目的/用途別に選定ポイントを解説します。
学習(トレーニング)
大量のデータを長時間かけて何度も計算するため、GPUの計算性能と扱うモデルやデータ量に比例するVRAMが重要です。さらにNVLink/NVSwitchなどの高速GPU間接続でサーバー内のボトルネックを排除し、ノード間はInfiniBandで広帯域かつ低遅延に統合することが望ましいです。分散学習ではこれらの帯域設計が実効性能を大きく左右します。
推論
AIが学習したモデルを使って結果を返す処理です。
ここでは、応答の速さと同時に処理できる数が重視されます。
学習時ほどGPU間の連携は必要ないため、1台あたりの処理性能や省電力性・拡張のしやすさを優先するとよいでしょう。
HPC〈FP64〉
流体解析や構造解析など、科学技術分野のシミュレーションでは、高精度な計算と広いメモリ帯域が鍵になります。
複数ノード間をつなぐ通信にはInfiniBandなどの高速ネットワークを使い、データ転送の無駄を減らす設計が求められます。
また、使うアプリケーションやライブラリがGPUに最適化されているかどうかも、性能を左右する重要なポイントです。
可視化/VDI
3D設計や映像レンダリングなどの用途では、描画性能とvGPU対応が重要です。同時接続数、解像度、映像圧縮などの制約を確認し、必要な表示品質を満たせる構成を選びましょう。
サーバー性能
GPUサーバーを選ぶ際は、GPUの搭載形式や接続設計が性能発揮の鍵になります。
SXMタイプのように基板へ直接実装する方式は高密度で冷却効率が高く、PCIeタイプは拡張性に優れます。用途に応じて最適な形式を選ぶことが重要です。
GPU同士をつなぐNVLinkやNVSwitchは、データ転送を高速化し、学習やHPC(高性能計算)の処理効率を大きく向上させます。さらに、サーバー間を接続するInfiniBandなどの通信方式は、複数ノードで分散処理を行う際の同期性能を左右します。こうした接続設計が最適でない場合、GPU本来の能力を十分に引き出せない可能性があります。
また、GPUを制御するCUDAなどのソフトウェア環境や、MPIによる分散処理の最適化も、実際の運用性能を大きく左右します。これらの仕組みが適切にチューニングされていれば、計算の無駄を減らし、より高い実効性能を得られます。
オンプレミスやハウジングで導入する場合は、筐体内の配線設計や冷却方式も安定稼働に関わるため、評価の対象に含めましょう。
コスト
TCOを比較すると、長期の常時稼働においてはハウジングやオンプレミスにコストメリットがあります。一方で、短期運用や段階拡張なら、初期費用が抑えられるクラウドが有利になりやすいです。ただし、クラウドはスケール幅や料金レンジ、課金単位をよく確認しておかないと、想定より運用コストがかさむ可能性があります。
コスト面に不安があるなら。初期費用0円からデータセンターでGPUサーバーの運用をスタートできるサービスを検討してみてください。 シーイーシーでは、最新の高性能GPUサーバーを初期費用0円で導入・運用できる「スターターパック for GPUサーバー」を用意しました。HPCやAI開発に適した構成をすぐに利用できます。さらに、導入前の性能検証や運用相談、コスト試算のサポートも行っており、初めてGPUを導入する企業様でも安心してスタートできます。
詳しくは以下のページをご覧ください。
お客様のDX実現を支援するシーイー…
スターターパック for GPUサーバー | シーイーシーデータセンター
最新の高スペックなGPUサーバーをお客様の資産として持たずに、初期費用0円でご利用いただけるサービスです。データマイニング、ブロックチェーン、AI、機械学習などに活用…
サポート体制
ハード/ソフトの保守窓口、パーツ供給、マルチベンダー時の切り分け責任、SLA(対応時間・復旧目標)などの範囲について、事前に確認しておくことをおすすめします。選定段階で検証結果や導入事例を確認し、要求される性能・運用・保守要件に適合するかをチェックすることが重要です。クラウドは提供地域/在庫/帯域仕様の更新が発生する場合があり、より新しいインスタンスタイプへ切り替える前提を運用計画に組み込むことが推奨されます。
BCP(事業継続計画)の観点から、二重化(予備機・電源・ネットワーク)や復旧手順の策定といった災害対策も必要です。GPUサーバーを自社設備で運用したい場合、オンプレミスでは自前で災害対策をしなければなりませんが、ハウジングへ移行すれば設備面での不安が解消されます。
シーイーシーでは、高負荷・高消費電力のGPUサーバーを安定稼働させたいお客様に向けて、「GPU・HPC対応 高負荷サーバーハウジングサービス」を提供しています。専用データセンターに設置することで、電源・空調・ネットワークといったインフラの負担を軽減し、GPUの性能を最大限に発揮できます。
また、利用電力に応じた柔軟な料金体系を採用しており、無駄のないコスト運用が可能です。監視・保守体制も整備されており、障害時の迅速な対応や災害対策にも対応。高密度・高負荷環境でも安定稼働を維持でき、AI開発やシミュレーションなどの重要な計算処理を長期にわたって安心して実行できます。
詳しくは以下のページをご覧ください。
お客様のDX実現を支援するシーイー…
GPU・HPC対応 高負荷サーバーハウジングサービス|シーイーシーデータセンター
GPUサーバーをデータセンター内に預かるサービスを消費電力に応じた価格設定で提供します。データマイニング、ブロックチェーン、AI、機械学習などに活用されているGPUサー…
まとめ:未来のビジネス成長を支えるGPUサーバー
GPUサーバーは多数のコアによる強力な並列演算能力を持ち、機械学習からHPC、3D可視化まで、幅広い業界のビジネススピードを加速する次世代の中核基盤です。要件に応じてクラウド/レンタル/オンプレ/ハウジングを適切に選択し、性能・コスト・運用・サポートを最適化することで、企業のDX化と新規事業創出を継続的に後押しします。
シーイーシーでは、お客様のDX実現を支援するさまざまなサービスを提供しています。サーバーの導入・運用でお困りごとがありましたら、ぜひお問い合わせください。
データセンターに関連する記事はこちら
-
【ホワイトペーパーダウンロード】サポート終了迫る、富士通製オフコンの最適な移行先プラットフォームとは
-
【ウェビナー】【クラウド全面移行の難しさ】柔軟性と統制を実現するハイブリッドクラウドとは~データ主権とBCPを考慮した、メガクラウドとオンプレの“いいとこ取り”を実現する~
-
数十テラ規模の大容量データを守るためガバナンス・リスク管理を実現する国内データストレージ選定ポイント ~ランサムウェア対策、ハイブリッド環境構築、データ主権、ユースケースを踏まえて解説~
-
GXとは?カーボンニュートラルとの違いや企業が今取り組むべきこと
-
ICT分野の環境負荷の見直しでGXを推進!実質再生可能エネルギー由来のグリーンデータセンター提供開始
-
【オンライン相談会】データセンター利用で働き方とオフィスを見直しませんか? ーサーバーの運用管理はデータセンターにお任せくださいー
-
データセンターとは?種類や選定ポイント、クラウドとの違いまで徹底解説
-
あなたの知らないデータセンター バーチャルツアーで内部の「ヒミツ」を見学しませんか?
-
kVAって何?初心者でもわかるデータセンターの電源の話